Creating Wiki-Style Sites with Large Language Models (LLMs)
Use LLMs like GPT-4 and transcription tools like Whisper to automate creation of Wiki-style sites with thousands of pages.


8 min read
Many websites can be characterized as “wikis”. Wikipedia is obviously the most prominent wiki, but there also exist many subject-specific wikis.
Creating wikis has typically required immense manual work. With the advent of Large Language Models (LLMs) at or above the quality of GPT-31, it is now possible to automate the creation of the majority, or perhaps the entirety of wikis.
In this article, I provide a framework to automate generation of wikis.
Why Create a Wiki? (Hint: $$$)
Some people enjoy digging holes to nowhere - you could make a wiki for absolutely no reason at all. You also might be motivated to make a wiki due to altruistic motives to some community.
If you’re an altruist or a hole-digging masochist, feel free to continue reading. But the rest of you should be interested because wikis can make you some decent money.

What I’m calling “Wikis” are a special case of what various people call “niche sites”, “authority sites”, or “content sites”. They’re all different words for the same thing: a website with articles concentrated in some particular niche which aims to rank high in search engines for particular searches.
Then, when a user comes to the site via search engines, you monetize them typically with ads, and affiliate links, but you can also potentially monetize them - depending on the subject matter - with any other monetization strategies found on the Internet: consulting, selling books/courses, selling leads, selling an app, etc.
I’m writing in this article purely on data architecture/pipeline design, but I just want to preface that there is a point to the whole exercise.2 Don’t go buying a Bugatti just yet, but a monthly payment on a used Camry? Very much in reach.3
Why Wikis in Particular are Suited for LLM-Generated Content
On wikis, the majority of the articles can be classified into a set of well-defined “collections”, and the articles within each “collection” have a very well-defined structure.
Consider, for example, this wiki for the TV show Breaking Bad:

A significant portion of those 2,069 articles fit into the following collections:
- Recap of Season X
- Recap of Episode X
- Character X
Each article within one of these collections will have a similar structure. Consider the outline of the articles for the Hank Schrader and Steven Gomez articles.
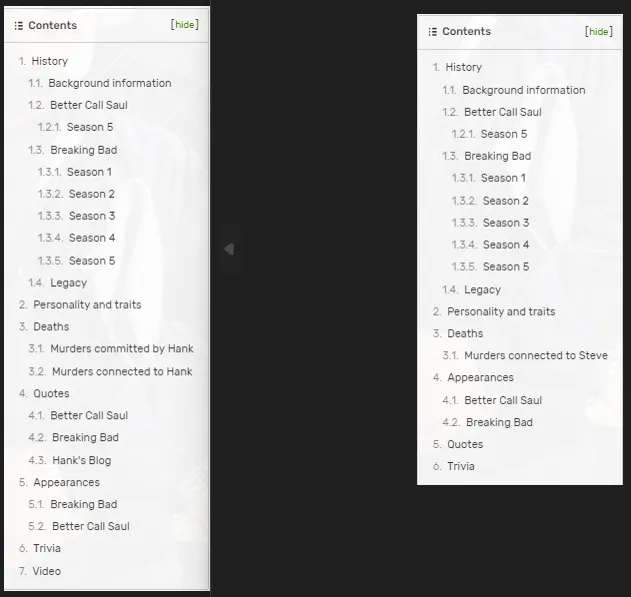
Steve Gomez’s outline is a strict subset of Hank Schrader’s outline; it’s just that some of the sections in Hank’s outline don’t apply to Steve.
This regularity of structure means that - if you provide an LLM with the right data - you only need a single prompt to generate all articles for characters in Breaking Bad.
You have to pay a fixed cost of creating a data pipeline which provides the LLM the data with which to write the article, but the variable cost of creating an article for an additional character will be close to zero.4
Structure of Content-Generation Pipeline
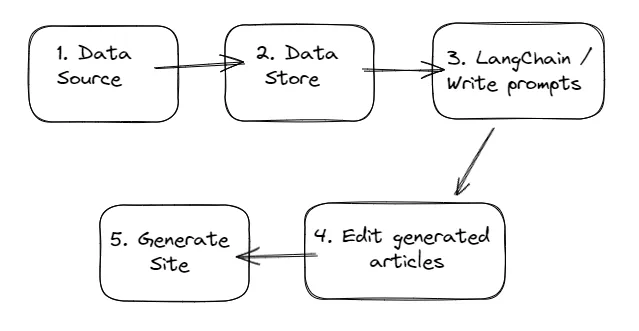
The above figure outlines at a high level the different components and how they feed in to each other. Let’s define each component so that you develop an understanding of how they feed into each other.
Finding and Parsing Data
A wiki, and most of the Internet, rarely involves original research. Instead, it’s summarizing and synthesizing others’ research and content.
Books, interviews, podcasts, YouTube videos, journal articles, or other websites could all potentially be data sources for your wiki. What’s essential for consumption of these sources by LLMs is that you have some method of converting the data source to text, since LLMs are able to generate text only with text prompts.5
Problems to solve
- What data sources are important for the questions asked by future readers of your wiki?
- How do you acquire those data sources?
- How do you convert those data sources to text?
Tools you might use
- OpenAI Whisper to transcribe audio
- Python to scrape websites
Store your Data
Next, you’ll need to store your data in a way such that for a given piece of content you want to create, the data for that article is retrievable.
For example, if you want to write a summary of Season 5 Episode 3 of Breaking Bad, you’ll need to store your data - such as the subtitles of the show - in some sort of system, such as a relational database, in which “Season 5 Episode 3” is a key.
Problems to solve
- What should your database schema be?
- How do you ingest the raw files into the database?
- Where do you deploy the database?
Tools you might use
- CSV Files
- Relational databases (e.g. PostgreSQL)
- Document databases (e.g. MongoDB)
- SQL and/or ORMs
- Parquet files in S3 Buckets
Data Pull + Prompt Design
Now, you’ve got your data prepared, but you have to - for a given piece of content - pull your data and tell the LLM what you want it to do with it.
Going back to the Breaking Bad example, you may feed the LLM the subtitles of the show, and then ask it to create a summary of the show.
In this stage, you’ll spend some time experimenting and playing around with different prompts, and then when you have a suitable one, you can apply it to all your data.
Problems to solve
- What query or set of queries provides the raw data about which you will instruct the LLM?
- What template or series of templates gets you the desired result?
- How do you calibrate hyperparameters of the LLM?
- For a given prompt, how many runs of a template do you need to generate a satisfactory result?
Tools you might use
- LangChain
- GPT
- BARD
- SQL and/or ORMs
Edit Generated Articles
Depending on your quality needs, you may need to edit your generated articles. If done manually, this reduces the gains from automation, but even if done manually - there are tools such as Grammarly which can make editing quite quick.
For the main project in which I’m applying this framework, I’m able to get by with zero editing.
Problems to Solve
- Are you content with the LLM’s results, or do you need to edit the article some more?
Tools you might use
- Manual proofreading
- Grammarly
- LLMs (if you’re creative, you can use LLMs to edit LLM generated articles)
Generate Site
Finally, once you have your articles, you need to actually generate the web pages on which those articles will arise. While this is the last stage of the pipeline, it’s actually something which should be done upfront.
At the very least, you should have some sort of wireframes for your wiki created for your wiki before you begin developing a data pipeline. If not, you run the risk of collecting data or writing articles you will not actually use on your wiki.
Problems to Solve
- Which framework will you use to build the site?
- How will you design the site?
- How will the site be organized?
Tools you might use
- Wordpress
- Webflow
- Static Site Generators (e.g. Astro, Hugo, Gatsby)
Conclusion
I like writing about topics I care about - like this article - and I like money. However, I don’t like money enough to ever write an entire wiki-style site myself. If you are like me, hopefully this article whetted your appetite for discovering how LLMs can help you create large wikis.
After reading this article, you should not now feel prepared to build such a site, unless you’ve already done so in the past.
For every one of the five steps I’ve identified above, there are several choices you’ll have to make between different options. Additionally, within each section, there is significant glue code that has to be written and various hiccups that may arise.
Next Steps
I have developed a specific implementation of this framework: scraping data with Python, transcribing audio with Whisper, storing data in PostgreSQL, wrapping the database in a Directus API, writing prompts with LangChain and GPT-4, and generating articles with Astro.
In upcoming articles, I will provide an end-to-end demonstration of a small example project generating a wiki using most or all of these tools. Subscribe to my email list (below on mobile or on the sidebar on desktop) and you’ll get notified of all my new posts.
In the know
Subscribe to get my newest posts straight to your inbox.
I won't send you spam. Unsubscribe at any time.
Footnotes
It’s possible the appropriate cutoff here is GPT-3.5. ↩
There are two primary pushbacks to the possibility of monetizability of AI-generated wikis. First, search engines may punish AI-generated content. Second, eventually LLMs trained on wikis may provide the same answers that do wikis, making wikis obsolete. I’ll comment on these concerns in future articles. ↩
Future articles will crunch numbers on website monetization. For now, trust me, I’m a doctor. ↩
The variable cost will be the cost of querying the LLM, and the cost of any editing - if necessary - on top of the LLM generated article. ↩
There are many managed solutions for text extraction from all of these sources. In future articles I’ll discuss some such solutions, though I will mostly discuss DIY solutions such as OpenAI Whisper. ↩
In the know
Subscribe to get my newest posts straight to your inbox.
I won't send you spam. Unsubscribe at any time.